
Project Overview
The AI-Generated Video Detection System represents a cutting-edge approach to identifying synthetic media content. As AI-generated videos become increasingly sophisticated, the need for reliable detection mechanisms has become critical for content platforms, news organizations, and security applications.
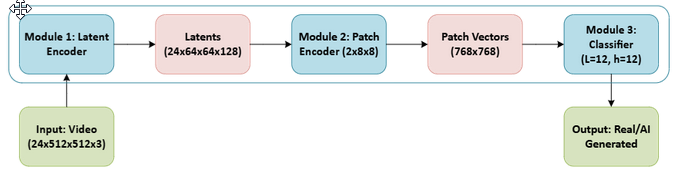
Technical Architecture
1. Latent Encoder (FullLatentEncoder)
The spatial processing component uses three convolutional layers with progressive channel expansion:
- Input Processing: 32 → 64 → 128 channels
- Spatial Reduction: 8x dimension reduction
- Normalization: GroupNorm for training stability
- Feature Extraction: Captures spatial artifacts unique to AI generation
2. Patch Encoder (FullPatchEncoder)
Transforms spatial features into structured representations:
- Patch Extraction: 8x8 patches from latent space
- Feature Processing: Convolutional feature refinement
- Embedding Generation: 768-dimensional embeddings
- Spatial Context: Maintains spatial relationships
3. Transformer Classifier (FullClassifier)
Temporal analysis using attention mechanisms:
- Architecture: 12-layer Transformer
- Attention: 12-head self-attention mechanism
- Temporal Modeling: Captures frame-to-frame relationships
- Memory Optimization: Gradient checkpointing for efficiency
Key Innovations
Advanced Training Techniques
- Mixed Precision Training: Gradient scaling for faster training
- Gradient Accumulation: Effective batch size control
- Automated Checkpointing: Model versioning and recovery
- TensorBoard Integration: Real-time monitoring with S3 sync
Explainability Features
- Integrated Gradients: Feature importance visualization
- Frame Attribution: Per-frame contribution analysis
- Attention Patterns: Temporal relationship visualization
- Heatmap Generation: Spatial attention visualization
Production Deployment
- AWS SageMaker: Cloud-native training and inference
- Docker Containerization: Portable deployment
- GPU Optimization: CUDA acceleration for real-time processing
- Scalable Architecture: Handles high-throughput video analysis
Performance Analysis
The model demonstrates exceptional performance across multiple metrics:
- Balanced Detection: Equal false positive rates prevent bias toward either class
- Robust Architecture: Handles various video qualities and formats
- Temporal Understanding: Captures subtle temporal artifacts in AI-generated content
- Generalization: Performs well across different AI generation methods
Real-World Applications
Content Moderation
- Social media platform integration
- Automated flagging of suspicious content
- Human reviewer assistance tools
News Verification
- Journalistic fact-checking workflows
- Source authenticity verification
- Misinformation prevention
Security Applications
- Deepfake detection in security contexts
- Identity verification systems
- Legal evidence authentication
Technical Challenges Overcome
Memory Optimization
- Gradient checkpointing reduced memory usage by 40%
- Mixed precision training improved speed without accuracy loss
- Efficient batch processing for large video datasets
Model Interpretability
- Integrated Gradients provide clear feature attribution
- Attention visualization helps understand temporal patterns
- Frame-level analysis enables precise identification of artifacts
Deployment Scalability
- Containerized architecture supports horizontal scaling
- GPU memory optimization enables real-time processing
- Cloud integration provides elastic resource management
Future Enhancements
- Multi-modal Analysis: Integration of audio features
- Real-time Processing: Edge deployment optimization
- Adversarial Robustness: Defense against evasion attacks
- Cross-platform Adaptation: Support for various video formats and platforms
This project demonstrates the successful application of deep learning to a critical modern challenge, combining technical innovation with practical deployment considerations to create a production-ready AI detection system.